在2018年,隨著中國聯通持續推進數字化轉型,用戶查詢手機話費賬單、下載電子發票的渠道已變得非常便捷和多樣化。無論是為了報銷、對賬還是個人理財,掌握正確的方法都能事半功倍。本指南將為您詳細介紹2018年期間,如何查詢聯通手機話費單以及如何獲取電子發票。
一、話費賬單查詢方法
查詢聯通手機話費賬單,旨在了解月度消費明細、套餐使用情況、增值業務費用等。2018年,用戶主要通過以下官方渠道進行查詢:
- 中國聯通手機營業廳APP(官方推薦)
- 操作路徑:登錄APP后,通常在首頁或“服務”板塊找到“查詢”或“話費/詳單”入口。您可以查詢實時話費、賬戶余額,以及詳盡的“歷史賬單”。歷史賬單會清晰列出月固定費、語音通話、數據流量、增值業務等每一項的費用構成。
- 優勢:數據實時、準確,可查詢近6個月(部分用戶可達12個月)的歷史賬單,且界面直觀。
- 網上營業廳
- 操作路徑:通過電腦瀏覽器訪問中國聯通網上營業廳官網,使用手機號和密碼登錄。在“自助服務”或“我的聯通”欄目下,找到“話費查詢”或“賬單查詢”即可。
- 優勢:適合需要在電腦上進行詳細分析或打印賬單的用戶,展示信息更為全面。
- 短信查詢
- 操作指令:發送指定指令(如“CXYL”查詢余額,“CXZD”查詢賬單)至10010。系統會以短信形式回復當月或上月的大致賬單信息。
- 注意:此方法信息較為簡略,適合快速了解大致費用。
- 客服熱線
- 撥打10010:根據語音提示轉接人工服務,向客服人員提供身份驗證信息后,可申請查詢賬單詳情。客服也可通過短信方式將賬單詳情發送至您的手機。
二、電子發票開具與下載指南
自2017年底國家稅務總局推行增值稅電子普通發票以來,2018年中國聯通已全面推廣電子發票服務。電子發票法律效力、基本用途與傳統紙質發票相同,且更方便保存和報銷。
開具與下載核心渠道:中國聯通手機營業廳APP
- 開票前準備:確保您的手機號已實名認證,且需要開具發票的月份話費已結清(即出賬并完成繳費)。
- 具體操作步驟(以APP為例):
- 登錄聯通手機營業廳APP。
- 在“服務”頁面,找到“查詢”大類下的“電子發票”或直接搜索“電子發票”。
- 進入后,選擇“開具發票”。系統會列出可開具發票的月份(通常是近6個月)。
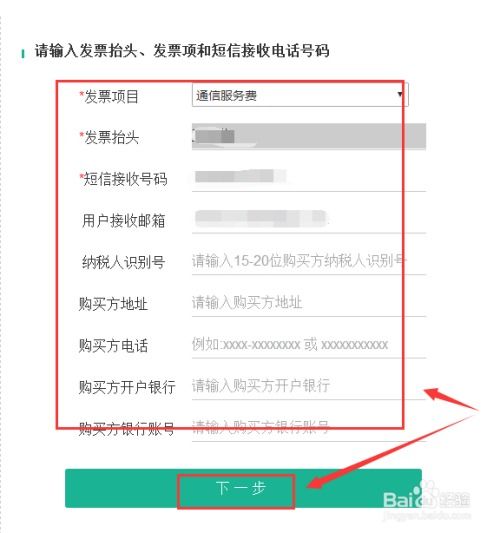
- 選擇需要開票的月份,填寫或確認發票抬頭信息(個人或單位名稱)、納稅人識別號(如需單位報銷,此項必填)。
- 提交申請后,系統會實時生成電子發票。您可以在“我的發票”或“發票歷史”中查看。
- 點擊已開具的發票,即可進行“下載”(保存PDF版本到手機)、“發送郵箱”或直接“打印”。
- 其他渠道:
- 網上營業廳:登錄官網后,在“自助服務”中找到電子發票開具功能,流程與APP類似。
- 實體營業廳:攜帶本人身份證原件,前往聯通自有營業廳,可請工作人員協助打印已開具的電子發票或指導操作。
三、重要提示與票據信息咨詢服務
- 賬單與發票區別:話費賬單是消費明細清單,用于了解費用構成;電子發票是稅務報銷憑證,基于已支付的話費金額開具。
- 開票時間:建議在每月出賬期(一般為每月3日后)且完成繳費后再申請開具當月發票。
- 信息準確性:開具單位發票時,請務必與單位財務部門確認準確的發票抬頭和納稅人識別號,一旦開具,信息通常無法修改。
- 咨詢服務:如遇賬單疑問、開票失敗、信息錯誤等問題,最有效的解決方式是:
- 直接咨詢聯通官方客服:撥打10010,轉人工服務。
- 使用APP在線客服:在手機營業廳APP內通常有在線客服入口,可進行文字或語音咨詢。
- 前往營業廳:對于復雜問題,攜帶有效證件到線下營業廳辦理是最直接的方式。
在2018年,通過中國聯通的官方數字化平臺,用戶已能輕松實現話費賬單的透明化查詢和電子發票的即時獲取,極大地方便了日常管理和商務報銷需求。